Episode 16: DeepSeek - Understanding the basics
I have recently joined a mentorship program for building Multi-Agent LLM Applications and will be sharing my learnings in a series of detailed blog posts over the next couple of weeks.
Check out Week 1 post.
Check out Week 2 post.
Updates from Week 3:
Apart from working on our projects this week, we got a chance to meet Boqi Chen who is a PhD Student at McGill University. He walked us through the fundamental concepts related to DeepSeek R1 and v3 models and gave a rundown of all the hype around it. The video is up on Youtube, check it out here. Here are detailed notes on it by Amir Feizpour. In this post, I share some of the things I learned from the session and from the additional research I did on the topic.
Let’s get right in!
Why DeepSeek model took the world by storm?
“(DeepSeek) model is actually compressed to the point where you can just take the model, run it on a smaller cluster. And if I’m choosing between Llama or paying OpenAI to host GPT for me or running DeepSeek locally, I will choose DeepSeek locally because it’s cheap. And so the part doesn’t sit because, yes, they are faking the cost as low, but it doesn’t matter what price they set because it’s open source.” [6]
- Open-Source: It is open-source, allowing you to download, fine-tune, and run it locally without data being transferred elsewhere. It is an “open-weight” model which means that the trained parameters are publicly available with a permissive MIT license.
- Cheap: Its inference compute is cheaper i.e. the time and energy needed by the model to reason through the request and give a response comes at a fraction of the cost it took to build commercial reasoning models like OpenAI’s o1, without compromising the quality of the response.
- Reasoning capability: Its reasoning capability is pretty impressive for an open-source model.
- Unsupervised: At certain stages of training, the model doesn’t require NLP data; it can reason and learn autonomously.
Timeline of DeepSeek

-
May 2023: DeepSeek AI is founded by Liang Wenfeng, transitioning from High-Flyer’s Fire-Flyer AI research branch.
-
November 2023: Release of DeepSeek Coder, the lab’s first open-source code-focused model.
-
Early 2024:** Introduction of DeepSeek LLM (67B parameters) and subsequent price competition with major Chinese tech giants.
-
May 2024: Launch of DeepSeek-V2, praised for its strong performance and lower training cost.
-
Late 2024: DeepSeek-Coder-V2 (236B parameters) appears, offering a high context window (128K tokens).
-
Early 2025: Debut of DeepSeek-V3 (671B parameters) and DeepSeek-R1, the latter focusing on advanced reasoning tasks and challenging OpenAI’s o1 model.
What are some of the novel implementation techniques in DeepSeek model?
“DeepSeek v3 remains the top ranked open weights model despite being around 45x more efficient in training than its competition. Bad news if you were selling GPUs. DeepSeek R1 represents another huge breakthrough in efficiency both for training and inference. The DeepSeq R1 API is currently 27% times cheaper than OpenAI’s o1 for a similar level of quality.” [6]
- They switched to 8-bit floating point numbers, which are more memory-efficient.
- They developed a clever system that breaks numbers into small tiles for activations and blocks for weights. So instead of just using a single word for a token, they use multiple blocks.
- Using pure reinforcement learning (RL) with carefully crafted reward functions, they managed to get models to develop sophisticated reasoning capabilities completely autonomously.
What is multi-head latent attention?
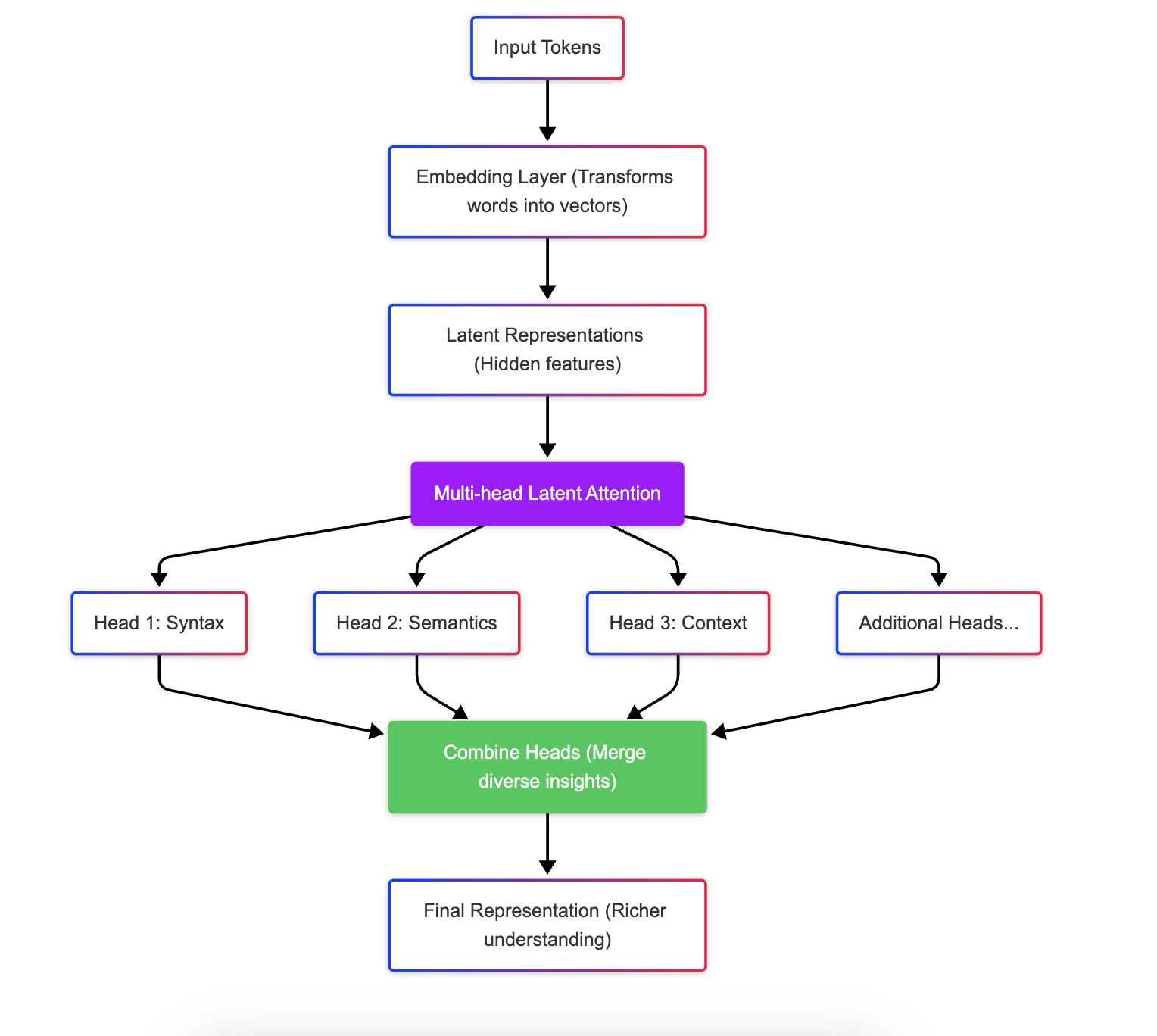
Imagine you’re reading a complex paragraph and have several colored markers. Each marker lets you underline different themes—like one for emotions, one for facts, and one for ideas. By combining all these perspectives, you gain a richer understanding of the text. Similarly, multi-head latent attention lets DeepSeek R1 capture various aspects of the input, making its overall understanding and responses more nuanced and accurate.
This part of the mechanism allows the model to look at different parts of the input simultaneously. Instead of having a single focus, the model splits its attention into multiple “heads,” each of which can focus on different patterns or relationships within the data.
“Latent” refers to the hidden representations the model builds internally. Instead of directly attending to raw input (like words or pixels), the model applies attention to these latent, learned features. This allows it to capture deeper and more abstract relationships. By focusing on latent (hidden) representations, the model can capture abstract patterns that may not be obvious from the raw data. This results in more accurate and nuanced understanding.
What is a mixture-of-experts model? [8]
“DeepSeek v3 is also a mixture of experts model, which is one large model comprised of many other smaller experts that specialize in different things, an emergent behavior. One struggle MoE models have faced has been how to determine which token goes to which sub-model, or “expert”. DeepSeek implemented a “gating network” that routed tokens to the right expert in a balanced way that did not detract from model performance. This means that routing is very efficient, and only a few parameters are changed during training per token relative to the overall size of the model. This adds to the training efficiency and to the low cost of inference.” - Dylan Patel, SemiAnalysis [8]
What is H100, H800, A100?
“All eyes are on how long the profitless spending on AI continues. H100 rental pricing is falling every month and availability is growing quickly for medium sized clusters at fair pricing. Despite this, it’s clear that demand dynamics are still strong. While the big tech firms are still the largest buyers, there is an increasingly diverse roster of buyers around the world still increasing GPU purchasing sequentially.” - Dylan Patel and Daniel Nishball [1]
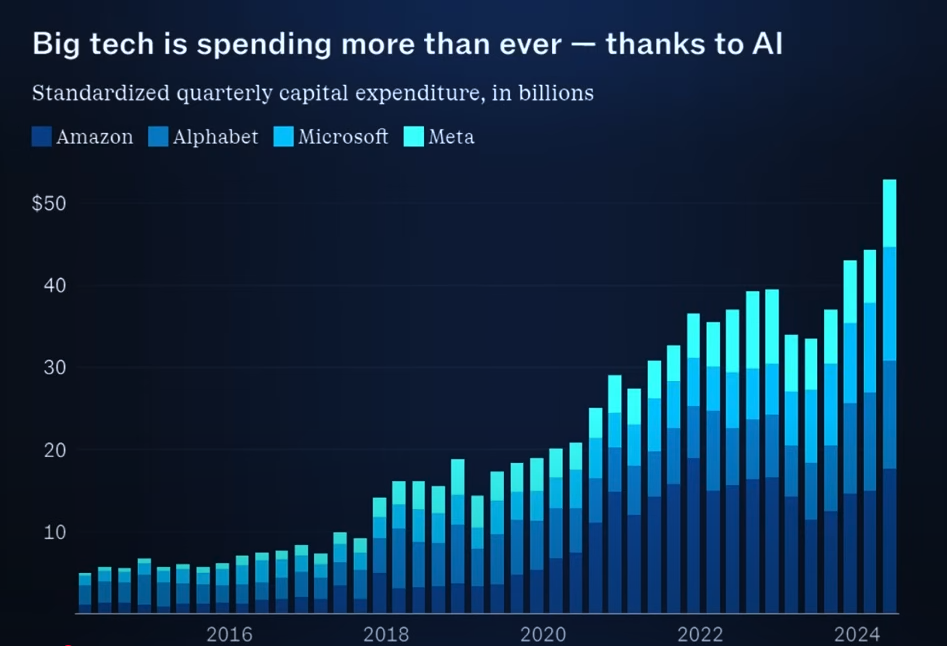
In today’s AI gold rush, tech companies are investing heavily in AI infrastructure, even though these investments might not be immediately profitable. There can be three main outcomes of this:
- If you underinvest and AI is real, you’ve missed an opportunity.
- If you overinvest and AI is real, you’re all set!
- If you overinvest and AI is not real, you have still invested in a lot of useful assets that can be utilized for a bunch of other stuff.
So what are these assets?
NVIDIA is the leading provider of GPUs (Graphics Processing Units) that power most modern AI applications. Their hardware is designed to handle the massive parallel processing needed for training and running deep learning models. There are three main GPUs currently being used to train AI models.
[2]
| GPU | Released | Features | Performance |
|---|---|---|---|
| A100 | 2020 | 80GB HBM2e memory*, Ampere architecture | Strong performance in machine learning, scientific computing, and data analytics |
| H100 | 2022 | 80GB HBM3 memory (higher bandwidth), Hopper architecture, has “Transformer Engine” | Up to 9x faster AI training performance. Up to 30x faster inference performance |
| H800 | 2023 | A modified version of H100 specifically sold in the Chinese market due to export regulations | Lower overall performance compared to H100 |
- HBM2e: High bandwidth memory, second generation, enhanced.
As everyone is saying, in this AI gold rush, NVIDIA is selling shovels!
What are Chain-of-Thought models? [4]
“Similar to standard prompting techniques, CoT prompting inserts several example solutions to reasoning problems into the LLM’s prompt. Then, each example is paired with a chain of thought, or a series of intermediate reasoning steps for solving the problem. The LLM then learns (in a few-shot manner) to generate similar chains of thought when solving reasoning problems. Such an approach uses minimal data (i.e., just a few examples for prompting), requires no task-specific fine-tuning, and significantly improves LLM performance on reasoning-based benchmarks, especially for larger models.” - Cameron R. Wolfe [5]
Think of it as leveraging the “long anticipated power of what’s called reinforcement learning (RL) with the power of the transformer architecture”. This has proven very valuable. You tell the model that it needs to maximize a reward function and it continuously fact-checks itself in order to do that. Historically, the biggest flaw of transformer models was its tendency to hallucinate and be stuck in the same wrong loop because the model is always trying to predict the next token from the current token so it cannot course correct itself. But combining it with RL which is normally used in robotics, is a gamechanger!
When you write a prompt in ChatGPT, it immediately gives you a response. That is because traditional LLMs generate answers by predicting the next token based on learned patterns.
But a Chain-of-Thought (CoT) model generates intermediate steps — a kind of internal “reasoning” before arriving at a final answer. Think of it as outlining your thought process while solving a problem.
CoT models are typically based on transformer architectures, but they are modified to produce intermediate outputs. The software architecture is designed to allow the model to “think out loud” — generating not just the answer but the steps leading up to it.
The additional inference steps in CoT modeling require more compute per query. This means modern GPUs (like NVIDIA’s H100) that are optimized for high throughput and efficiency are becoming increasingly important compared to older generations (like the A100). CoT models often need to store and process more intermediate data. Advances in GPU memory, such as the transition from HBM2e to HBM3, provide the necessary bandwidth and capacity to handle these extra computations efficiently.

What are the different scaling laws of LLMs?
Pre-training scaling law:
Model performance increases if we have more and more tokens as training data, more model parameters and the more flops of compute we spend on training the model.
We have seen this in the past - GPT 3 to GPT 4, there was an order of magnitude increase in the amount of data, compute, money, energy and everything that went into those models. And as a result, GPT 4 very clearly is a lot smarter than GPT 3!
Inference time compute (Test Time Compute):
Traditionally, when you have asked GPT a question like “Tell me the population of the world”, it will quickly spit out an answer based on its “predict the next token” training. But with new reasoning models, when you ask such a question, they will spend some time thinking through it, generate intermediate tokens and reason, fact check, reality check their response before giving the final answer. That takes time and energy. So now such reasoning models will not only require more pre-training compute but also test time compute to give a response. Deepseek has been able to build such a reasoning model using a fraction of the cost for OpenAI’s reasoning model o1.
This is the reason why the DeepSeek debate is so relevant. Everyone is now questioning Sam Altman’s pitch for a $500 billion cluster based on the pre-training scaling law. What if we 10x the size of the model (and the resources used for it) and the model only improves by 2%.
What is Jevons Paradox?
Jevons Paradox is a concept in economics that shows an unexpected twist: when technology improves the efficiency of using a resource (such as a GPU), it can lead to an overall increase in the consumption of that resource (increasing its demand), rather than a decrease.
Why can it be deceiving?
In past decades, some market analysts and investors predicted that increased efficiency in automobiles and industrial machinery would lead to a decline in demand for fossil fuels such as oil and coal. Acting on this assumption, they sometimes sold off stocks in energy companies (market crash!).
Instead of demand falling, the lower cost of energy use (thanks to improved efficiency) spurred greater industrial activity and more widespread use of automobiles, leading to overall higher energy consumption. Companies that sold off stocks based on the expectation of declining demand ended up missing out on the sustained or even growing profitability of these firms.
Same is the case with NVIDIA’s GPUs. Just because a company came up with an efficient way to use NVIDIA’s GPUs, doesn’t mean the demand for it is going to go down. In fact, we can expect to see more AI now and higher demand for GPUs.
What is ELO Ranking?
“The clear target that most have in mind is matching OpenAI and even surpassing them. Today, many firms are within spitting distance of OpenAI’s latest GPT-4 in Chatbot ELO, and in some ways such as context length and video modalities, some firms are already ahead.” - Dylan Patel and Daniel Nishball [1]
Origin:
Elo Rank is a scoring system that was originally developed for chess. It rates players based on the outcomes of matches against each other. The more wins you have against higher-rated opponents, the higher your Elo score becomes.
Elo Ranks for LLMs:
For Large Language Models (LLMs), one popular way to evaluate performance is by comparing the outputs of two models on the same prompt. Evaluators (either humans or automated systems) decide which response is better based on criteria like coherence, factual accuracy, and creativity. A model that consistently produces better responses (winning more pairwise “matches”) will accumulate a higher Elo rating. Chatbot Arena is one place where you can try it.
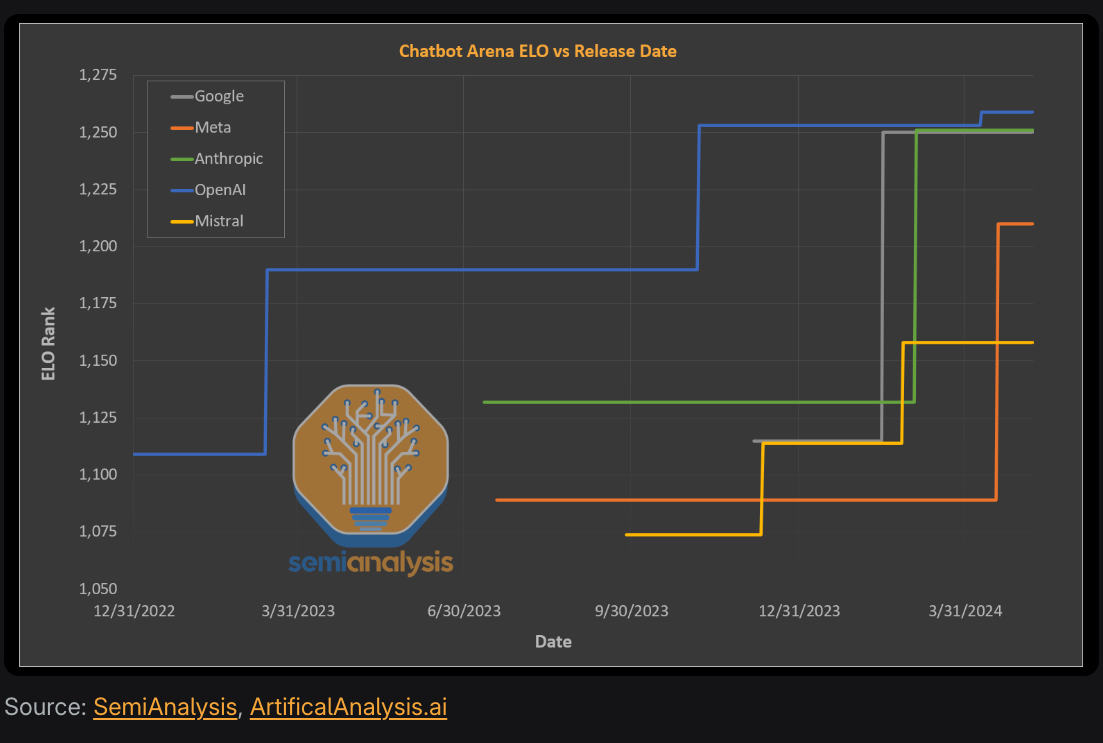
The image shows that as compute increases, a tech company can become capable of developing a model that can match OpenAI’s GPT-4, regardless of whether it is open or closed source.
Favorite quotes:
-
“There’s still the question of why should 1 company extract the majority of the profit pool from the technology? … The Wright Brothers airplane company in all its carnations across many different firms today isn’t worth more than $10,000,000,000 despite them inventing and perfecting the technology well ahead of everyone else. And while Ford has a respectable market cap of $40,000,000,000, that’s just 1.1% of NVIDIA’s current market cap.” [6]
-
“You you could say (DeepSeek) is like watching the Communist Party write a love letter to decentralization..It’s not a love letter to decentralization. It’s a middle finger to our Our chips … And our trade export controls.” [6]
-
“I do really care about clean energy, but I think AGI will be so powerful that we don’t need to worry about climate change in the short term. And so let’s just burn all the natural gas and oil and get to AGI. And then AGI will literally figure it out and just do carbon sequestration, And we’ll have so much powerful superintelligence that we’ll be building Dyson spheres and, like, we’ll be able to just completely change the environment however we want. So we shouldn’t let this hold us back, which is a very interesting” [6]
-
-
References:
[1] OpenAI Is Doomed? – Et tu, Microsoft?
[2] Performance Comparison: NVIDIA A100, H100 & H800
[3] Nvidia (NVDA) is Selling the Best Shovel in the A.I. Gold Rush
[4] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
[5] Chain of Thought Prompting for LLMs
[6] DeepSeek Update, Market Crash, Timeline in Turmoil, Is VC Cooked, Zero Cope Policy
[7] Understanding DeepSeek R1
[8] [DeepSeek Debates: Chinese Leadership On Cost, True Training Cost, Closed Model Margin Impacts H100 Pricing Soaring, Subsidized Inference Pricing, Export Controls, MLA] (https://semianalysis.com/2025/01/31/deepseek-debates/)