Episode 14: Week 1 of Building Multi-Agent Applications - A Bootcamp
I have recently joined a mentorship program for building Multi-Agent LLM Applications and will be sharing my learnings in a series of detailed blog posts over the next couple of weeks.
My blog posts will be divided into two sections:
- The Bootcamp: What I learned from the bootcamp during the week.
- The Basics: What I had to learn on my own to understand #1.
The former talks about the interesting insights shared by industry practitioners and experts in this field and the latter is on the basics and fundamentals of generative AI technology that I had to catch up with in order to understand these complex discussions.
Let’s get right in!
Disclaimer: All memes in this post are AI-generated using Predis.ai
There is a short demo video of a personal vacation planning AI assistant built using no-code LangFlow at the end of this post!
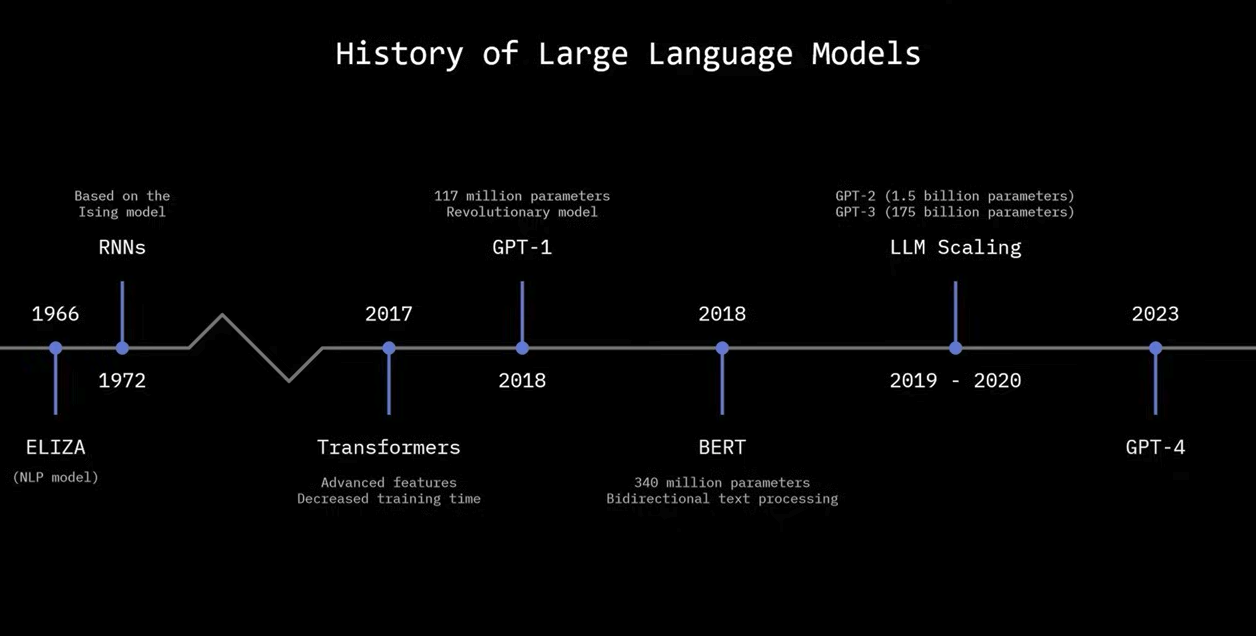
The Basics:
What is the difference between monolithic models and compound AI systems? [2]
A model on its own has limited knowledge and finds it hard to adapt to new problems. Suppose I train an LLM on a fixed training dataset and it is perfect for tasks like summarizing documents and drafting emails but when I ask it a specific question like, “What is my company’s HR policy on taking sick days?” it would not give a correct answer because it does not have access to my personal data.
Therefore, people have started building compound AI systems in which multiple, specialized LLMs are integrated into an application that can also include non-LLM models, to perform different workflows. For example, there will be an LLM specialized in summarizing documents, another that specializes in translation and together they can work together within the application to perform different tasks and produce more accurate results. These LLMs have access to databases, can write specific search queries using different tools, remember past interactions and therefore give specific answers that can be more accurate. The system can also contain non-LLM models such as a traditional ML based recommender system which can be used as a tool by the agent to perform its tasks with reasoning.
LLM agents using an external database to augment their knowledge is the example of the most common AI compound system called Retrieval Augmented Generation (RAG). [1]
What is an agent? [3]
Traditionally, control logic in systems was designed using fixed instructions. The code followed a predictable and deterministic path. But in an agentic flow, multiple LLM agents can be used to guide the flow of the application. They can be used to perform specialized tasks using special tools, different data sources and a history of past interactions with the end user. This allows the agents to become increasingly specialized in their tasks and gain better domain knowledge with each iteration. So, in summary, an agent has three properties:
- Memory: Remembers past interactions to guide new tasks.
- Tools: Access to different tools and data sources to perform the task.
- Planning: Has the reasoning capability to plan out its tasks to maximize the reward.
What is the difference between agents and LLMs? [3]
It is possible to build a compund AI system with non-agentic flow while using LLMs. In such a system, LLMs will perform different tasks they are trained to perform but the workflow being executed will more or less be pre-determined. For example, an LLM can be asked to provide the user with all the national holidays of the country being given as an input. This LLM will not use any reasoning to come up with the answer. It will simply return a pre-determined list of dates that are national holidays in the given country and are always the same for that country. The response will never change for the same prompt.
However, in an agentic system, the LLM has some level of “agency” or autonomy in the decision making process. If an agent is provided with different tools and uses reasoning to decide which tools to use to perform the task in a better way, then that is an agentic workflow. This is similar to the concept of policies in reinforcement learning - the mechanism by which the environment provides feedback to the agent about its actions. The agent learns a policy (a mapping from states to actions) to maximize its cumulative reward.
Just because a system is complex, doesn’t mean it is agentic but most complex workflows might benefit from an agentic solution!

How to decide between using a monolithic system and a compound AI system for your application? [3]
When the task at hand is simple, does not depend on past interactions, and involves only one function, then using a single LLM makes more sense than using LLM agents in a compound AI system.
Example: Summarizing documents.
But when the task involves several subtasks, when the reward function becomes too complex with multiple constraints for a single LLM, when the response depends not only on the user prompt but other data sources, then using multiple specialized LLMs (agents) makes more sense.
Example: A chatbot that assists users. In addition to user prompts, the agents need to access the company’s confidential policy documents to make decisions. The decision is supposed to optimize multiple factors such as conversion and retention. Coming up with a reward function that maximizes both is going to be a challenge so developing multiple agents that specialize in optimizing each of these constraints is more useful.
What is the lang family?[4]

LangChain:
- Open-source framework.
- Build, run, manage applications powered by LLMs.
- Chains different steps during the workflow such as:
- Take user prompt.
- Access external database.
- Remember context.
- Supports almost all models - closed source e.g. GPT4 or open-source e.g. LLama 3
- Has indexes which let you load documents or use vector databases to pull in external data.
- Has prompt templates. No need to hard-code prompts. Just customize templates for known tasks e.g. text summarization, translation etc.
- Allows the application to remember past interactions adding long term memory to the workflow.
LangGraph:
- Open-source library.
- Built on top of LangChain.
- Used to manage agents and their workflows.
- Useful for building applications that involve multi-agent workflows.
- Used when agents need cyclical interactions in their decision-making process.

LangFlow:
- If you are not that big on coding and want to build agentic applications powered by LLMs using a nice visual interface where you can drag and drop blocks, then this is the tool for you.
- Built on top of LangChain.
- Perfect for prototyping LLM based applications.
LangSmith:
- All-in-all platform that helps you develop, test, deploy and monitor LLM based applications.
- Can be used with both Langchain and LangGraph.
- Dashboards can be set up around the application to monitor LLM costs, latency and performance.

The Bootcamp
What is the product strategy formula for developing LLM based products? [5]
Without domain driven product design, service oriented and micro-service architecture, you cannot build rock solid agentic applications. Selling products where automation is masked as agentic workflow comes under “agentic washing”, which is deception. The product strategy for a good agentic application should be designed keeping in mind the following components:
- Product Vision
- Insights
- Challenges
- Approaches
- Accountability (North Star Metric)
The agent should have the following features: [9]
- Reasoning capability
- Long Term Memory
- Ability to perform tasks autonomously
- Integration
- Sensing

One example where an LLM product launch went badly for a big company? [6]
In Feb 2024, Air Canada’s customer service chatbot misguided a customer on the carrier’s refund policy on bereavement fares. When a customer asked the chatbot about the policy, the chatbot replied:
“Air Canada offers reduced bereavement fares if you need to travel because of an imminent death or a death in your immediate family…If you need to travel immediately or have already travelled and would like to submit your ticket for a reduced bereavement rate, kindly do so within 90 days of the date your ticket was issued by completing our Ticket Refund Application form.”
The page that the chatbot’s response linked to, which was Air Canada’s official website, contradicted what the bot was saying which resulted in the carrier losing the lawsuit and paying in damages. The chatbot was clearly hallucinating and extrapolating.
Air Canada ended up shutting down the chatbot and firing a bunch of data scientists. What could Air Canada have done differently? The chatbot should have warned users about potential inaccuracies in its responses.

One example of a rock solid LLM product launch? [7]
Navan (formerly TripActions) is an online travel management, corporate card and expense management company.
- Developed an AI-powered AI assistant named Ava which serves as a real-time data analyst for CFOs and finance managers.
- Uses OpenAI’s GPT-4 APIs, doing real-time analysis of the data, reporting to high level executives directly.
- It makes recommendations on how to save and manage the company’s finances more efficiently.
- “It also continuously learns and monitors spending patterns to provide tailored advice, helping organizations improve their bottom lines.”
What was Navan’s product strategy? [9]
- Product vision:
- Make data analysis of the company’s internal expenses less tedious.
- Workflow Insights:
- Uncertainty in the agent’s response is caused by the gap between the Information Needed by the agent and the information that the agent has. Navan’s challenge: Less visibility into travel expenses, complex travel policies.
- Information Needed is a function of the diversity of outputs, inputs and the how precise we want the agent to be. Navan’s challenge: Variety of expense formats and currencies.
- Information Have is a function of an agent’s past experience and the stability of the environment it is working in. Navan’s challenge: Variety of data sources. Changes in user behaviour.
- Challenges:
What challenges did they want to prioritize that could be solved with the AI product
- Lack of visibility into travel spend
- Difficulty to predict future travel costs
- Sensitive data
- Non-compliance with company’s policies
- Orchestration:
- How are different agents going to be organized?
- This involves dealing with potential clashes between agents’ responses.
- Guardrails:
- The agency of these agents should be bounded by their knowledge and what they are allowed to do
- Transparency and explainability of the responses they are giving
- Necessary for audits
- Data that is being consumed by the agents is not PII
Navan’s approach included limiting the dollar amount agents could approve for expense reimbursements, providing a summary of the reasoning behind every response, escalate unusual decisions taken by the agent to an actual human.
- Accountability/Evaluation:
- North Star Metric: % increase in efficient travel spend with the help of proxy metrics like % of repeat users, % of suggestions given by Ava that were actually implemented etc.
What is AI SDK 3.4 with Generative UI? [9]
Imagine asking a ChatBot:
“Help me plan an affordable vacation to Paris, including budget-friendly flights, accommodations, and activities?” and instead of getting a response in text form, you get a dynamic, interactive response including dynamic filters and clickable elements for tailored adjustments, e.g.
- A flight results card showing options sorted by price, departure time, and airline, the bot using its reasoning capabilities plus the data from all over the web.
- Filters for flights (e.g., “direct flights only”) and hotels (e.g., “4 stars and above”).
- Ability to add selected options to a shopping cart for seamless checkout.
Vercel’s AI SDK 3.4, released in September 2024, allows developers to build such applications.
What are the different steps in building user’s trust with your AI application? [5]
- Easy onboarding.
- Sufficient guidance.
- Example: ChatGPT’s starter prompts.
- Trust & verify.
- Example: Bard’s extension: Google’s Gemini fact-checks its AI responses against web pages, cited sources.
- Check on bias.
- Example: MidJourney’s AI generated images for “teacher” returned white women and for “professor” returned older white men.
- Fail gracefully (Chatbot should be humble enough to admit that it doesn’t have the answer to a particular question)
- Example: Google Docs Duet AI allows users to regenerate the response when they don’t like how the model has answered.
- Safe Landing.
- Example: Notion AI gives web links in addition to AI responses so the user can fact-check or explore further.
What are some of the components of a product requirements document for non-deterministic AI products: [5]
- Model requirements
- Which model to use?
- How big is the context window (e.g. how much memory do different agents need to have for their specializations.)
- Latency (is it fast enough?)
- Open vs Closed-source models ($$$)
- Need to fine-tune?
- Modality (i.e. in what form will the model take input and generate output e.g. text, image etc. )
- Data:
- Sources of training and feedback data.
- Ways to collect, prepare, store data.
- Training method: fine-tuning or RLHF.
-
Prompt requirements
-
AI User Experience
-
AI Testing & Measurement
-
AI Risks
- AI Costs:
- Data acquisition
- Model Fine-tuning
- Operational expenses with token usage
| Feature | Fine-Tuning | RLHF |
|---|---|---|
| Data Type | Labeled, task-specific | Rankings or feedback from humans |
| Objective | Improve accuracy for defined tasks | Align outputs with human preferences |
| Training Complexity | Relatively simpler | More complex (requires human input and reward modeling) |
| Outcome | Task-specific optimization | Improved alignment with user expectations, adaptability to subjective contexts |
| Example | Updating a language model to improve its medical terminology responses by training it on medical-specific data. | Human’s feeback on the quality of the essay returned by the chatbot |
Demo Time
This application takes a city name as input from the user, retrieves statutory holidays, and identifies the best surrounding cities, creating an itinerary complete with budget, weather forecasts, and travel recommendations for that city and its surrounding areas for each vacation date. Time to book those vacation days at your job!
While this is a pretty cool application, this is not purely agentic and therefore serves as a good example to learn about the difference between agentic and automated workflows.
Agent 1 and 2 are not actually agents but LLMs following a pre-determined workflow. Each agent in all most all relevant user queries will follow the same workflow without any autonomous decision making. It will always call the search API, look for holidays of the input city and neighboring cities and return the list. It will always give the same response for the same input city.
Agent 3, however, is truly agentic. Since it is using reasoning and planning to come up with an itinerary and the responses might change on the next iteration for the same input city.
One way to convert it into an agentic workflow would be to:
- Combine agent 1 and 2 to a single agent to give travel destination recommendations and the ideal dates to travel to those recommendations since this uses travel expertise and reasoning.
- Agent 3 can continue to be the planning and budgeting agent.
References:
[1] Large Language Models (LLMs) - Everything You NEED To Know
[2] What are AI Agents?
[3] LLM Agents, Part 2 - What the Heck are Agents, anyway?
[4] LangGraph vs LangChain vs LangFlow vs LangSmith : Which One To Use & Why?
[5] LLM Products vs Traditional Digital Products by Amin Bashi
[6] What Air Canada Lost In ‘Remarkable’ Lying AI Chatbot Case
[7] Navan Introduces World-First Generative AI Tool for CFOs and Travel Admins
[8] Bringing React Components to AI
[9] Building Agentic Products by Amin Bashi