Episode 13: Important Notes on Linear Regression
Linear regression is about modeling the linear approximation of the causal relationship between two or more variables.
Example:
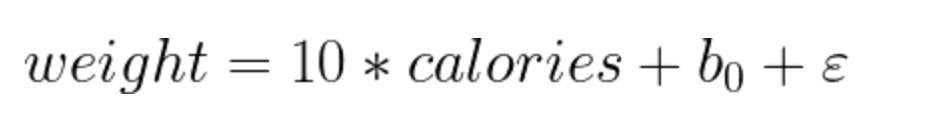
Here weight is the dependent variable and # of calories is the independent variable.

The model means that for each additional increase in calories, weight will increase by 10kg. b0 can be thought of as the baseline weight. Keeping calorie intake aside, this would be the baseline weight of the person on average.
(ε): Error term. The expected value of errors should be zero.
- What is the difference between correlation and regression?
- Definition:
- Correlation measures the movement of two variables i.e. if variable1 increases , does variable2 decrease or increase with it?
- Regression models causation i.e. change in variable1 (independent variable or regressor) causes change in variable2 (dependent variable).
- Symmetry:
- Correlation is symmetrical i.e. correlation of x and y is the same as correlation of y and x.
- Regression is one way i.e. If change in x causes a change in y then the other way around may not be true.
- Graphical Representation:
- Correlation is calculated as a single point.
- Regression is the best fitting line.
- Definition:
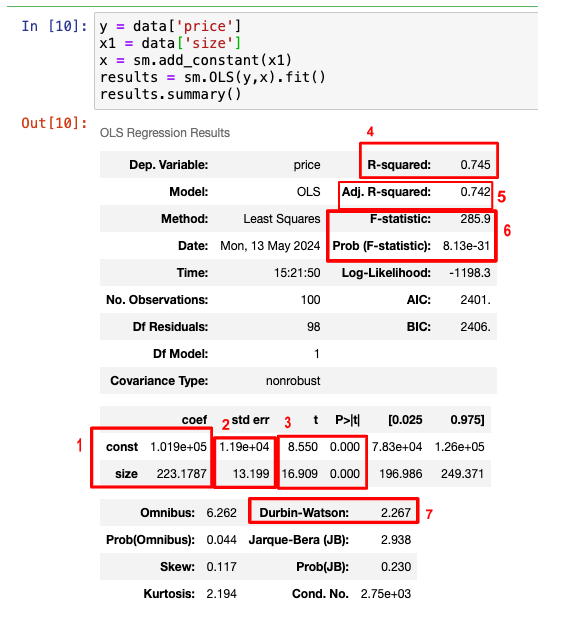
- How to interpret linear regression summary table we get from statsmodel library?
-
Coefficients: Here, ‘Price’ represents the predicted variable, and ‘Size’ is the independent variable. The table shows that the regression model will look like this:
Price = 101900 + 223*Size - Standard Error: Accuracy of the prediction for each variable. The lower the error, the better the estimation.
- T-statistic and p-value:
- We can use this to assess the significance of variables.
- Null hypothesis is that the coefficient is 0.
- When b0 = 0, it means the regression line passes through 0. We normally don’t check this statistic for the intercept.
- If b1 = 0 it would mean that size is not important in determining the price.
- If p-value is low i.e. 0.000 - it means we can reject the null hypothesis that the coefficient is zero and accept the alternate hypothesis i.e. choose the variable as it is significant.
- R-squared: The ratio of SSR to SST (defined in the sections below). Measures the goodness of fit. Used in univariate regression.
- How much total variability in the dataset have we captured through the model?
- 0 = regression line explains none of variability of the data.
- 1 = regression line explains all of the variability of the data.
- More significant variables means higher R-squared and better model.
- Adjusted R-squared: Same as R-squared but adjusted, so it can be used in multiple regression (more than 1 variable used to model the dependent variable).
- With each additional variable, the explanatory power of the model may increase or stay the same.
- Adjusted R-squared is always less than R-squared because it penalizes the excessive use of variables.
- F-statistic: Test for overall significance of the model.
- Null hypothesis is that all coefficients are simultaneously zero. Our model has no merit.
- Alternate hypothesis is that at least one coefficient differs from zero.
- If p-value is less than 0.05, the model is significant but when comparing two models, we can compare their F-statistic and decide which model has higher F-statistic and hence is more significant.
- Durbin-Watson test: Helps us check for auto-correlation.
- A value of 2 indicates no autocorrelation.
- Value < 1 or value > 2 is cause for alarm.
- How do we use the ANOVA framework to determine the quality of regression?
We look at the following error measures:
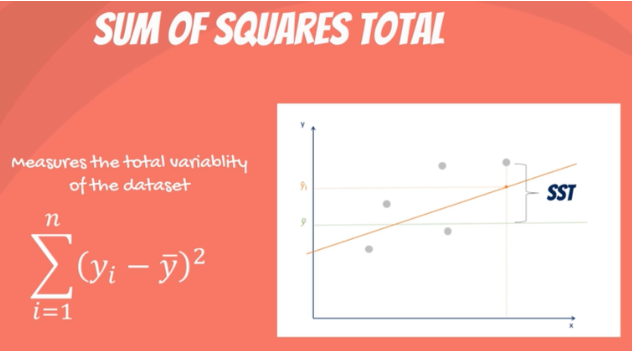
- Sum of squares total (SST) (difference between actual value and sample mean of y).
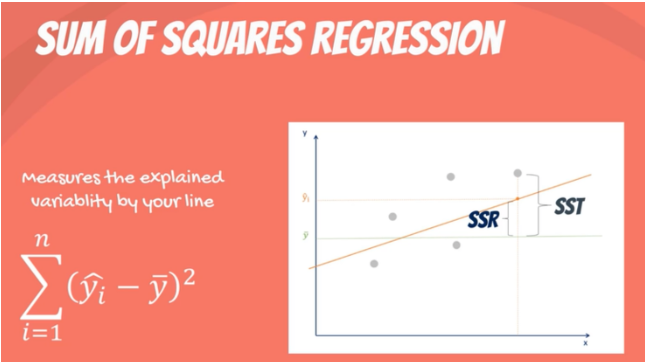
- Sum of squares regression (SSR) (difference between predicted value and sample mean of y).
- Sum of squares error (difference between predicted value and actual value)

Here is how these error terms are related:
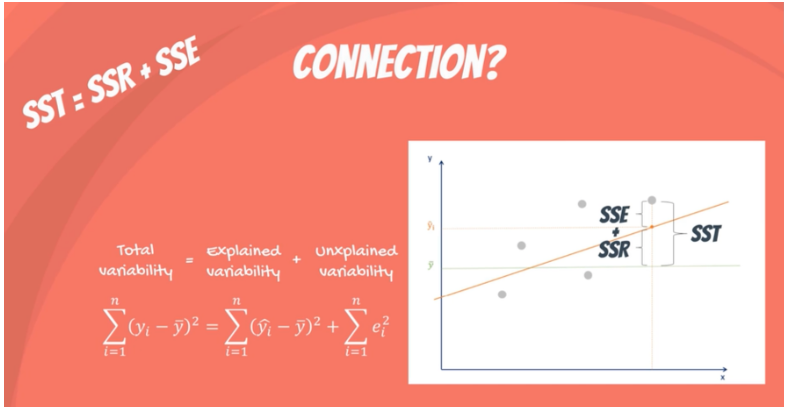
In Ordinary Least Squares Regression (OLS) we minimize the sum of squared errors to reduce unexplained variability. The model chooses the line that is closest to all the points.
- What are regression assumptions?
- Linearity:
- Definition: There is a linear relationship between dependent and independent variables.
- How to check it: Get pair plots of each independent variable with the dependent variable.
- How to fix: If the plots show there is a non-linear relationship, we take a log transform of the independent variable to make the relationship linear or use a non-linear regression model.
- No Endogeneity:
- Definition: Collinearity of independent variable (x) and error (e) is 0 for any x or e.
- Omitted variable bias: Happens when we forget to include an important variable.
- The regressors that are used in the model are correlated with the regressor that we didn’t use in the model (omitted variable) and that is why the used regressors end up being correlated to the errors.
- How to check it: calculate the covariance of error and independent variables.
- How to fix: Include all variables in the first iteration of the model fit and then exclude some of them based on their significance.
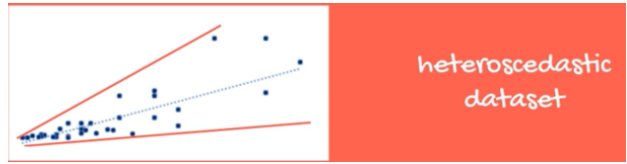
- Normality and homoscedasticity:
- Normality: Expected value of error is 0 and errors are normally distributed.
- Homoscedasticity: Errors should have constant variance.
- The conditions of normality is not required for the regression to be valid but it is required for the t-statistic etc. to be valid. If we have a large sample size then the central limit theorem applies and we can assume that errors are normally distributed.
- Below is an example of violation of homoscedasticity. Fixes: check OVB, remove outliers, log transformation of independent variables.
- No auto-correlation (serial correlation):
- Covariance of any two error terms should be zero.
- Highly unlikely in cross-sectional data (data taken at one moment in time).
- Highly likely in time-series data.
- How to check: Plot residuals and look for patterns.
- Durbin-Watson test.
- How to fix: There is no fix. This condition cannot be relaxed. It’s best to use ARIMA model for time series data instead of linear regression.
- No multicollinearity:
- No two variables should have a high correlation.
- Coefficients will be wrongly estimated if this assumption is violated.
- How to check: Check correlation of all pairs of independent variables.
- How to fix: drop one of them, transform both into one variable.
-
What is a log-log model?
In order to make the relationship between dependent and independent variable linear, we can take log of both. This is a log-log model. This can help us fulfill assumption#1 (linearity) and assumption#3 (homoscedasticity) for OLS.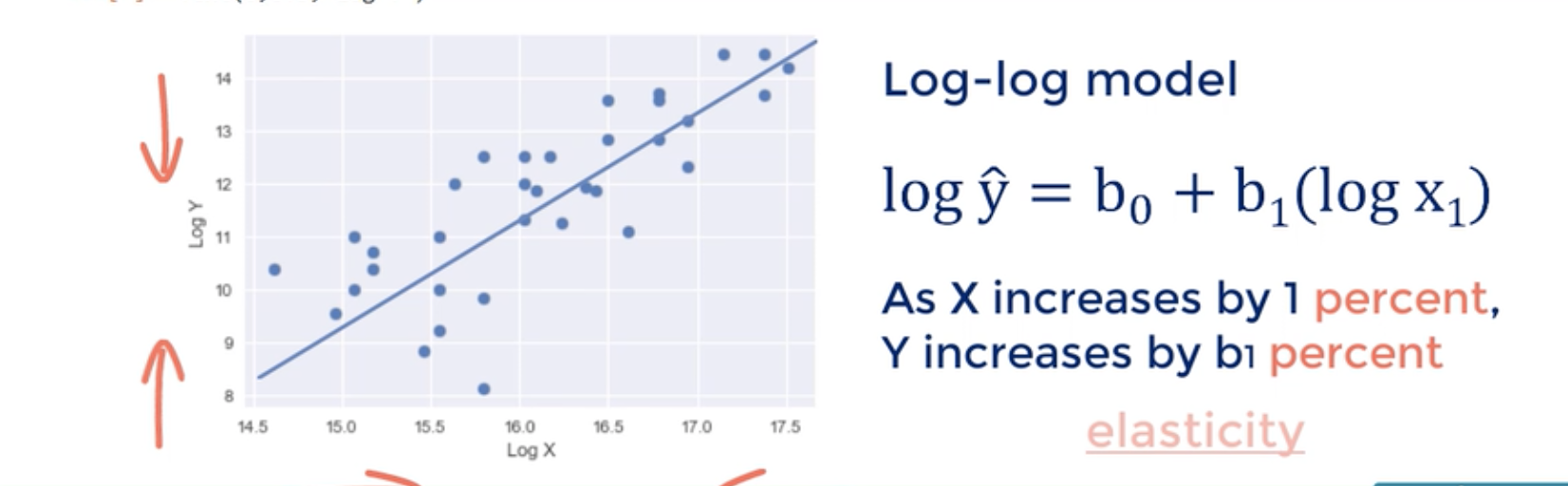
-
What are some other techniques apart from OLS in regression analysis?
- Generalized Least Squares
- Maximum Likelihood Estimation
- Bayesian Regression
- Kernel Regression
- Gaussian Process Regression
References:
[1] How To Perform A Linear Regression In Python (With Examples!)
[2] Data Science Career Track, 365 Data Science
[3] Memes by Jonah Garnick ‘23