Episode 11: Notes from Machine Learning Specialization by Andrew Ng
This is part of a series of posts on some of my notes from course on Machine Learning Specialization taught by Prof. Andrew Ng.
Concepts:
-
For anomaly detection, in what cases do we prefer supervised learning and when do we use unsupervised learning?
In anomaly detection, we are dealing with an imbalanced dataset.
- Unsupervised learning:
- when we have a very small number of positive examples (0 - 20 is common) and a large number of negative examples. Supervised learning: Otherwise.
- Anomalous behavior has no discernible pattern. Each time the anomaly can occur in a different way. Unsupervised learning methods e.g. density estimation are independent of this as they try to model the behavior of normally occurring phenomenon and everything outside it is considered as an anomaly.
- Choice of features for anomaly detection is extremely important.
- Supervised learning:
- 20 or more positive examples.
- Here we try to learn the behavior of anomalous examples. Based on the assumption that future anomalous examples will look like the existing ones.
- Choosing redundant or extra features doesn’t cause much harm as the algorithm takes care of it.
Examples:
- Fraud detection in banks, monitoring machines in data center (Unsupervised)
- Email spam, disease classfication, weather prediction (Supervised)
- Unsupervised learning:
-
What are some of the ways you can convert non-gaussian features to gaussian and why is it important?
If we are estimating the probability distribution of the negative (non-anomalous) examples using a gaussian distribution that it is important to convert all the features to a gaussian distribution.If x is some feature with non-gaussian distribution then we can convert it to gaussian through the following transformations:
\(log(x)\\ log(x + c\*)\) \(\sqrt(x)\\ x^\frac{1}{3}\)
* where c is some constant value selected by hit and trial. We add this to avoid log(0) case.
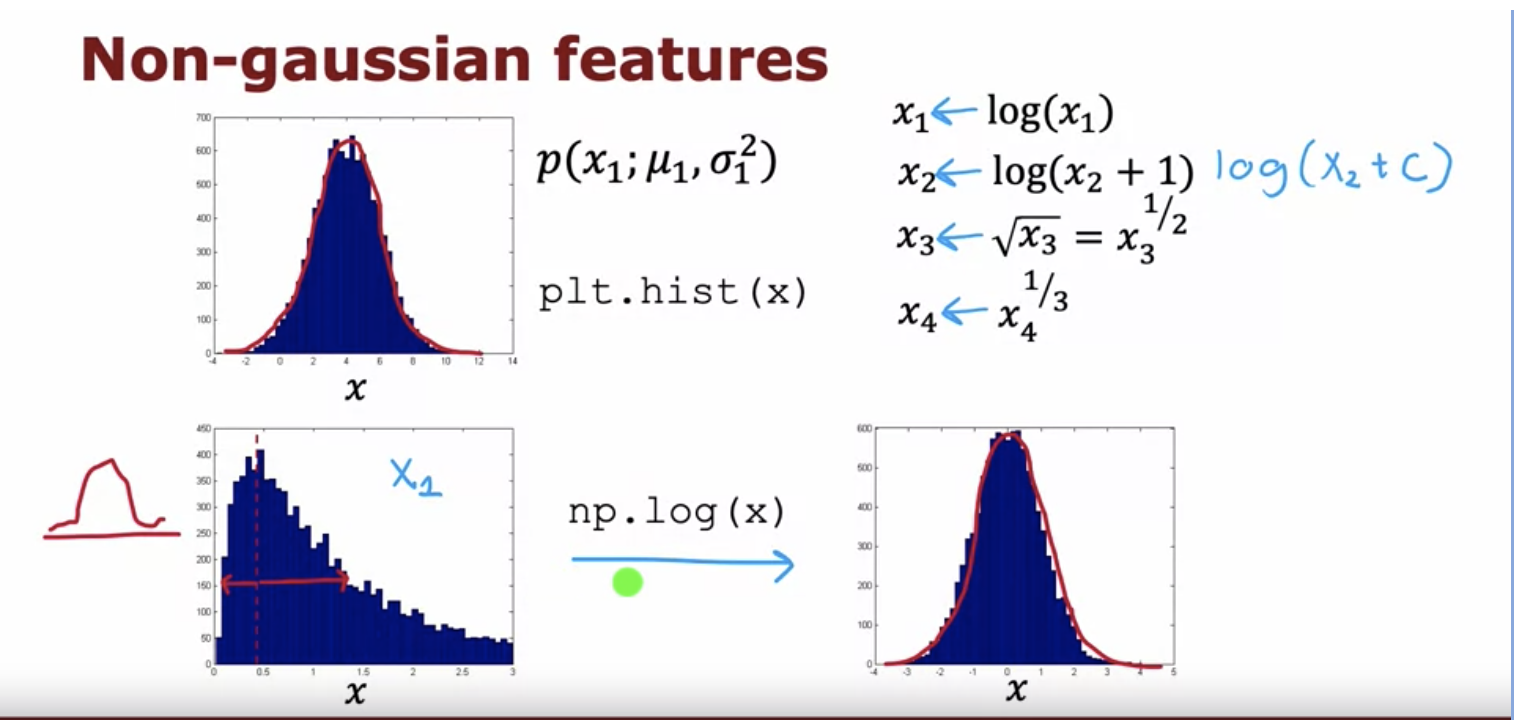
Source: Week 1, Unsupervised Learning, Recommenders, Reinforcement Learning by Andrew Ng -
What do we do when, after building our density estimation model we find out that the probability of an anomalous event is close to a normal event?
In these cases, it helps to come up with a derived variables e.g. ratio of a feature that takes a very small value for anomalies and a feature that take very high value in case of anomalies.
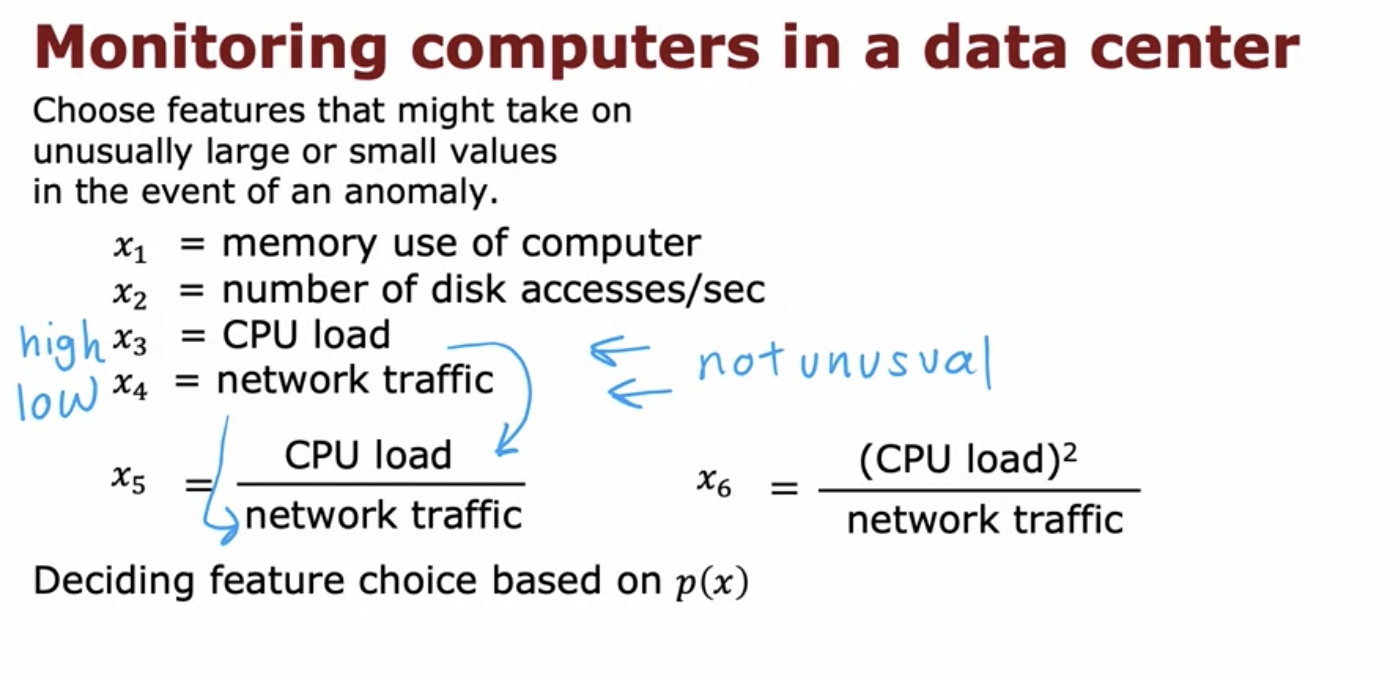
Source: Week 1, Unsupervised Learning, Recommenders, Reinforcement Learning by Andrew Ng -
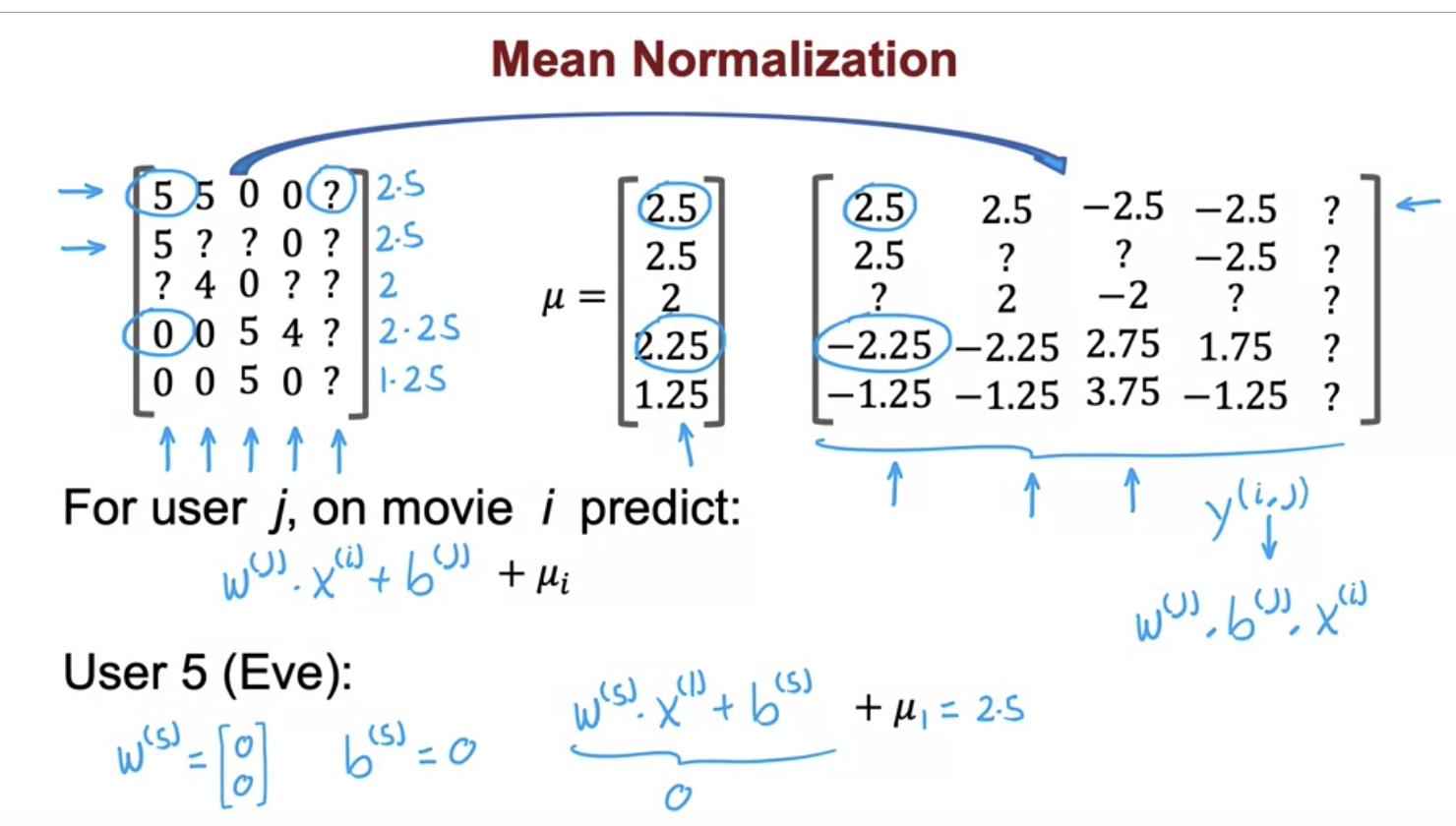
What is mean normalization, why do we do it when building recommender systems? When do we do it row wise and when is it done column wise?
Mean normalization is done by subtracting mean of every feature from each value of the feature. Generally, it is done to scale features. To bring all values to the same range. When it is divided by the range, the features are scaled.
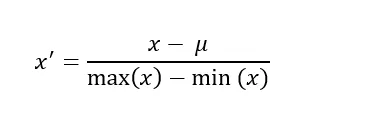
If the denominator is standard deviation, then it the process is called standardization. The resulting distribution has 0 mean and unit variance.
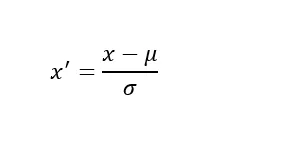
Optimization algorithms converge faster when the features are scaled.
In recommender systems, we only do mean normalization (subtract mean from each value of the rating in the per-item matrix) to fix cold-start issue. If a new user shows up in the system and we have not done mean normalization, then the algorithm will assume that the new user will give 0 rating to every movie. But after mean normalization, the algorithm will assume that the new user will rate each movie according to the average rating of that movie based on existing users. For this we do row wise mean normalization (items are in the rows and users are in the columns of the matrix).
If a new movie shows up and no user has rated it yet, then in order to estimate it’s ratings, we do column wise mean normalization. But this is not advisable.
Source: Week 2, Unsupervised Learning, Recommenders, Reinforcement Learning by Andrew Ng -
What is the difference between collaborative and content-based filtering?
-
Collaborative Filtering: Recommendations are based on ratings of other users who are considered similar to you.
-
Content based Filtering: Recommendations are based on user and item features to find a good match (with the help of dot product).
-