Episode 7: Demystifying the buzz words in Big Data
This week I made the following notes while taking the “Big Data Essentials: HDFS, MapReduce and Spark RDD” course on Coursera [1].
Concepts:
- What is scaling up and scaling out?
Scaling up means increasing the capacity of each server (e.g. have a single 8TB machine).
Scaling out means having more servers per data center (e.g. have several 1TB machines).
Scaling up has low latency (less time delay between request and response) while scaling out has higher latency.

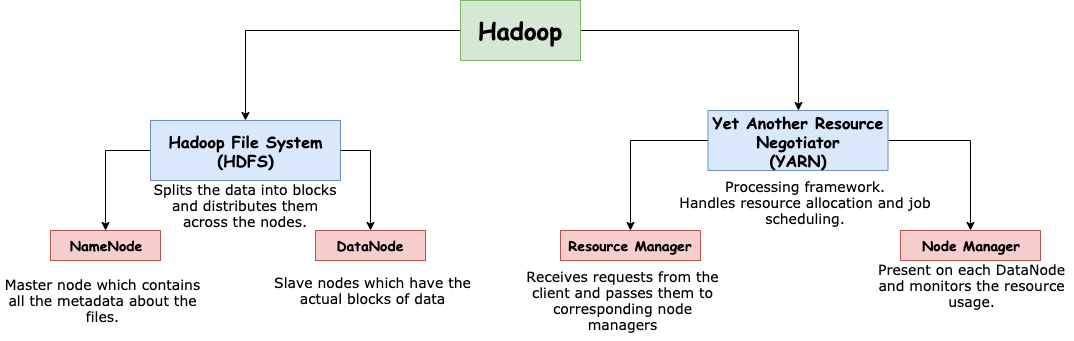
- What is Hadoop File System?
In 2003, Google published a paper on “Google File System” (GFS) [2]. In their paper, they described the architecture of a:
- scalable
- distributed file system
- with high fault tolerance
- using inexpensive commodity hardware.
In 2005, Apache developed Hadoop File System (HDFS) which is an open source implementation of GFS.
While GFS was originally written in C++, HDFS is written in Java. They both are designed to store petabytes of data across multiple nodes and can be used for data-intensive computing.
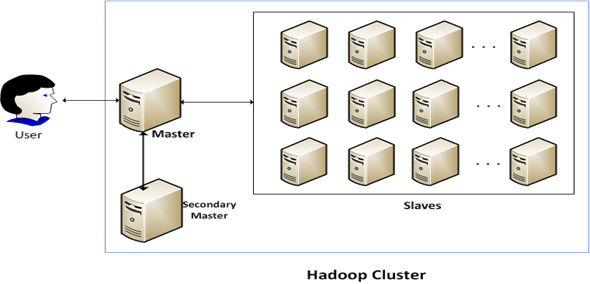
- What is a cluster?
A cluster is a network of computers. It is mostly composed of three parts [3]:
- Client: Applications accessing the data.
- Master Node: The root node that stores operation logs and acts as a manager in the network. The master does not store the actual file data and only the meta data (administrative information about the files, clusters etc.)
- Chunk servers: They act like slave nodes which store actual data and work under the directions of the master node. Each node stores a fixed size of data, ususally not more than 64 or 128 MB.
- How are HDFS and YARN related to each other?
- In a distributed file system (DFS), you can “append” into a file, but cannot “modify” a file in the middle. Why? [1]
DFS is based on a data usage pattern called “write-once-read-many” (WORM) which suits the kind of data collection that Google does. It also simplifies its API.
- What is Shared Nothing and Shared Disk?
These are two different kinds of data storage technologies. [6] In Shared Nothing, data is split up into small blocks and distributed across the nodes. It is completely partitioned and each node fully controls its subset of data.
In Shared Disk, each cluster has access to the data stored in disk. Each node has read/write permissions [7].
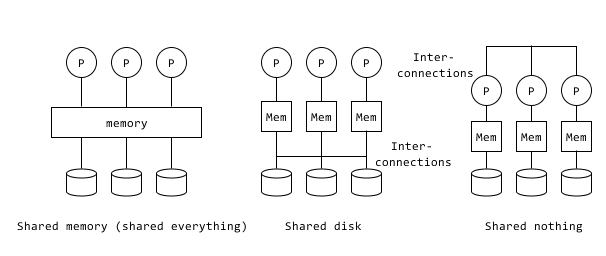
-
What is the difference between memory and storage?
Memory refers to RAM (Random access memory) which is used by th computer for executing more than one task at the same time. This memory is used for short-term. It is cleared when the machine is turned off.Storage referes to hard drive. It is used to store applications, operating system files for a much longer time.
Thought of the Week:
A couple of days ago I came across an article shared by Yann LeCun (the father of Convolutional Neural Networks (CNN) and also a professor at NYU), titled “The Most Important Court Decision For Data Science and Machine Learning” by Matthew Stewart [4]. This article gives a quick rundown of the famous Authors Guild vs Google case which dragged on for more than ten years, becoming the most important case study in the field of artificial intelligence and machine learning. In 2005, two famous publishers in the US sued Google for using copyrighted books for training their book search algorithms.
Google books search algorithm is a highly sophisticated machine learning algorithm for optimizing book search for users.
Recently, I searched for a couple of titles to understand how the algorithm actually worked. When I entered general keywords like “Lab” or “Blood”, it didn’t list the books based on word frequency in the existing database of books (because that would have simply given me a list of medical books), instead the algorithm also took into account the popularity of the books in other web searches (which is based on PageRank algorithm). For example, for “blood”, the book “Bad Blood” by John Carreyrou was among the top results. It is said that Google has scanned more than 15 million books and put them on web [5].
Anyhow, the end result of the famous case between Authors Guild and Google was that the Supreme Court eventually dismissed the lawsuit and Google was officially let off the hook. But the ruling helped establish some important precedents in Artificial intelligence, such as affirming that the “use of copyrighted material … to train a discriminative machine-learning algorithms (such as for search purposes) is legal” [4] But how would that fare in generative machine learning to produce deep fakes, is still an open question.
Until next time!
References:
[1] Big Data Essentials
[2] Google File System
[3] Analyzing Google File System and Hadoop Distributed File System
[4] The Most Important Court Decision For Data Science and Machine Learning
[5] Inside the Google Books Algorithm
[6] Shared Nothing v.s. Shared Disk Architectures: An Independent View
[7] Difference Between Memory and Storage in Computers