Episode 2: seq2seq Models
This week I listened to a podcast on “seq2seq models” on Data Skeptic [1], and this is everything I learned from it:
[Background: Data Skeptic is a show that is hosted by Kyle Polich who is a data scientist. In his podcasts, Kyle explains high level machine learning and data science concepts to his wife, Linh Da Tran, who does not have a computer science background. Sometimes their pet parrot Yoshi also gets dragged into the discussions and gets slain in the name of science!]
Summary:
seq2seq models were first introduced by Google for Machine Translation [7]. It provides an end-to-end solution in automated machine translation (e.g. English to Russian translation). Instead of converting each individual word to its target word separately, it uses grammer and context to translate a sentence in one language to another. It has an encoder-decoder architecture with Recurrent Neural Networks (RNN). A variable sized input sequence is encoded into a fixed sized “thought vector” and passed onto the decoder which decodes it to output the translated sentence. Other applications of seq2seq models include, Text Summarization, Conversational Modeling, and Image Captioning [3].
Concepts:
-
What advantage do decision trees have over logistic regression?
Logistic regression does not have the ability to capture non-linear features in the data. Tree-based models divide the space into smaller and smaller regions and can better capture the division between classes, provided they are well-separated. More on this here [2]. -
What is a common problem that many techniques in Machine Learning suffer from?
Most machine learning techniques rely on a fixed input and fixed output size. e.g. if you want to predict if a car would need maintenance on a certain part, you would need a set of features like mileage, output of a recent diagnostic test etc. The model is then trained on these features. We can only predict the output to the degree of the information content we have. -
A common joke in Natural Language Processing (NLP):
One time a group of data scientists attempted to use Mahcine Learning to translate the English sentence “The spirit is willing but the flesh is weak” to Russian. It came back as “The vodka is strong but the meat is rotten.” This shows how one-to-one translation is not a good solution in NLP. Context is important! -
What is a thought vector in seq2seq models?
In Machine translation we will have an input (e.g. English) and an output (e.g. Russian) but the model also has an internal numerical representation that the model sets according to the input. It only exists in the tensor space. It has no real meaning to anyone but it is specific to the algorithm/model. - Features of seq2seq models
- Adaptive.
- Variable sized input/output.
- Slides along the input sequence (just like a DNA clamp sliding along a sequence during DNA replication.)
- Maintains an internal state representation of the input sequence (an encoding) that it is constantly learning.
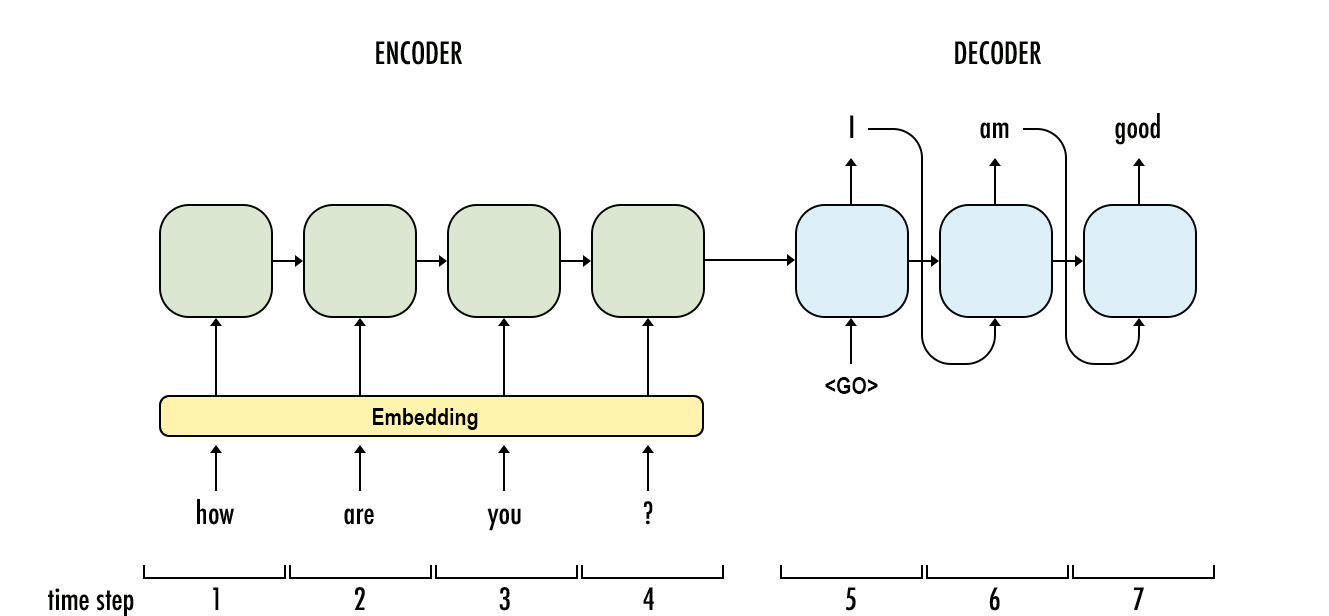
- Has two pieces: An encoder and a decoder. Encoder encodes the input sentence into a thought vector. The decoder decodes the thought vector into the output language.
- Structure: Input Layer -> Embedding Layer -> LSTM -> Dense Layer -> Output Layer
- What are some applications of seq2seq models?
Translation, Image captioning, Text summarization etc.
Seq2Seq Model animation [3]
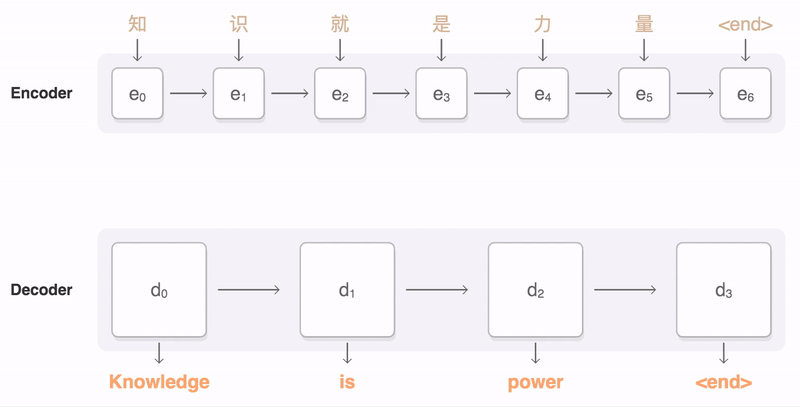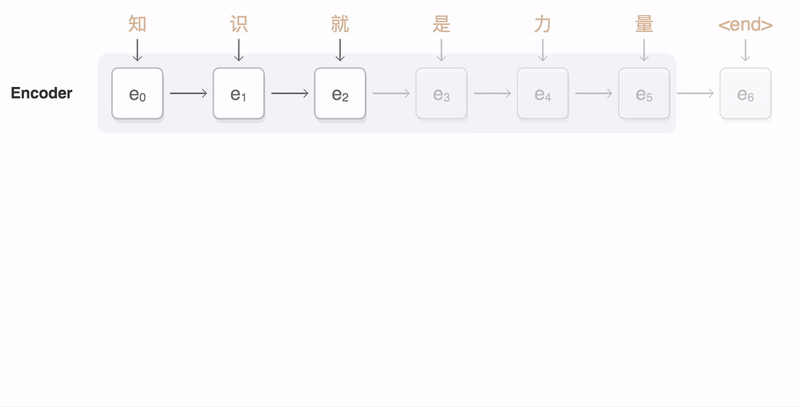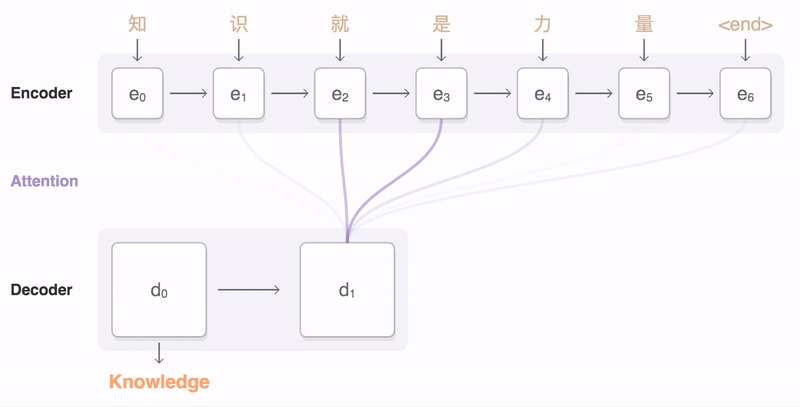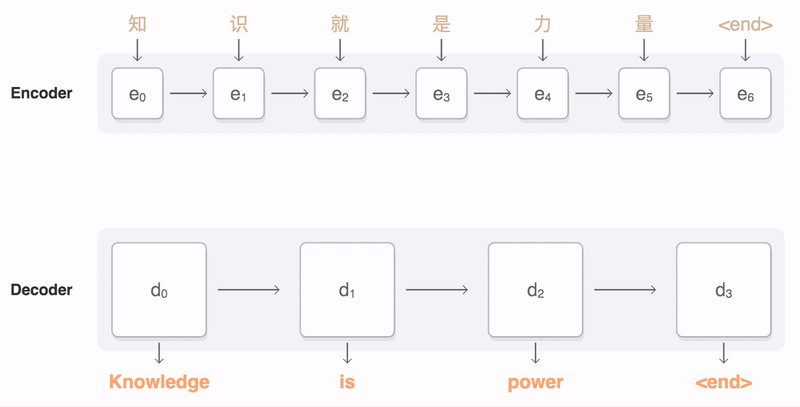
Seq2Seq Model [4]
Code of the Week:
This week I played with polynomial regression using different degrees to estimate C02 emissions from engine size. I calculated R2 score to compare the models. The source of the data is Government of Canada [5] and can be downloaded from [6]. Check out the coding exercise on my Github profile.
Thought of the Week:
I don’t know why I have so willfully ignored and underestimated the power of maintaining an active github account for the past 6 years of my engineering life. I remember being introduced to it during a summer internship when I was a sophomore at college, and also my careless use of git push and pull commands, my pulpy sophomore brain not quite wrapping around the version control theory as much as my mentor wanted it to. Keeping an active Github, I have come to realize, is nothing short of maintaining a coding journal (and I, who pride myself on owning more writing journals than I can ever manage, should have appreciated that sooner.)
So now I have decided to do small, self-assigned projects and post them on my github account occasionally, adding my own two cents to this deep, rich well of knowledge that exists freely on the web (totally ignoring the cool, seasoned computer scientists who are dismissively snorting at me right now for getting all giddy with excitement over discovering github so late in my life!)
References:
[1] se2seq, Data Skeptic
[2] Logistic Regression versus Decision Trees, BigML
[3] seq2seq models, Google Github
[4] Sequence to sequence model: Introduction and concepts
[5] Government of Canada
[6] Dataset
[7] Google Neural Machine Translation