Episode 1: Multi-output forecasting
This week I read the paper “Deep Multi-Output Forecasting - Learning to Accurately Predict Blood Glucose Trajectories” [2], and this is everything I learned from it:
[Disclaimer: Although the paper is a bit disappointing for an applications paper on diabetes, since it lacks some crucial details about study design, computational time, demographics, offline/online training/testing speed, however, I was still able to salvage certain important things from the wreckage.]
Vocabulary:
Signal-step forecasting problem: Estimate a future value of the signal for a single time instant using past values. e.g. blood glucose measurement.
Multi-step forecasting problem: Estimating multiple values within a future time horizon, recursively.
Multi-output forecasting: Estimating multiple values within a future time horizon, all at the same time instead of recursively.
Summary:
- This paper proposes a multi-ouput forecasting technique to predict blood glucose levels, using Recurrent Neural Networks (RNN).
- The authors use real-time data of 40 patients with 550k blood glucose measurements recorded via continuous glucose monitor (CGM) over the period of three years.
- Apart from using a many-to-many RNN, they have also used polynomial estimation in order to predict the underlying generative function of the signal. Overall, they propose four novel techniques which they compare with five baseline approaches including linear extrapolation, random forest and recursive RNNs.
- While choosing the loss function, they claim that previous works related to speech generation show that it is beneficial to treat multi-output forecasting problems as multi-class classification, and therefore, instead of predicting actual future values, the model predicts the probability mass function (PMF) over discretized values of the signal. Consequently, they use cross-entropy loss as the performance metric. The class showing the highest probability is considered as the predicted class.
- For train/test split, instead of a random split, they do a temporal split by adding the entirety of the final recording session to the test set and the second last session to the validation set, while rest of the data remains in the training set.
- The hyperparameter search space included model depth, recurrent layer size, initial learning rate and input normalization. + In the Results section, they make comparisons between deep vs shallow approaches as well as multi-output versus recursive models, concluding that deep multi-output models outperform other baseline models.
Concepts:
-
Why does multi-step forecasting (MSF) often have a poor long-term performance?
In MSF, we use the current prediction to make the next prediction recursively and any error introduced at one stage can enter a positive feedback loop (accumulate over time). -
What is the problem with multi-output forecasting?
It may not adequately capture dependencies among output predictions because it estimates all the future output values at the same time, instead of recursively. -
What is the difference between standard neural networks and RNNs?
Standarad Neural networks require fixed sized input but RNNs allow for variable sized inputs (becasue they encode the input signal into a fixed-sized, intermediate representation, sometimes referred to as the “thought vector”) -
What is the difference between autoregressive (ARN) and RNN?
RNNs use all the previous outputs for predicting the future value through hidden states.
ARN use a limited number of past values given directly as input to the next cell. It is like any typical feed-forward network. There is an interesting set of blogposts explaining this concept [3],[4].
| RNN architecture [7] | ARN architecture [6] |
|---|---|
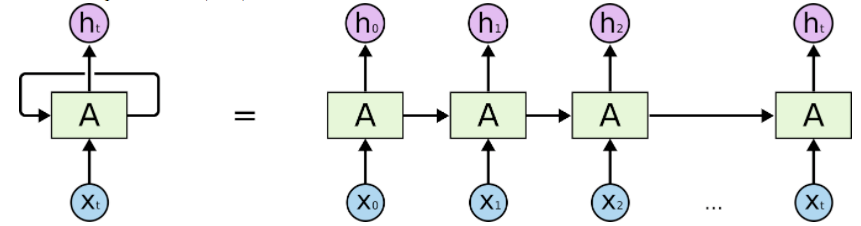 |
 |
-
What is ARIMA and how is it used for time-series forecasting?
ARIMA stands for Autoregressive integrated moving average [5] and it uses the following techniques:
AR - Auto-regressive: captures dependencies between present and past signal values.
I - Integrated: Makes the time-series stationary by differentiating the observations.
MA - Moving average: Takes a moving average of the observations and uses residual error ( = expected_value – predicted_value) -
What is early stopping in machine learning?
It is a form of implicit regularization that is done to achieve a balance between underfitting and overfitting in order to improve generalization. Approaches:
(1) Change the number of epochs. (Drawback: One has to train and discard several models for each value of epoch in order to find the best epoch.)
(2) If the performance on validation set start degrading after a particular epoch, stop the training. -
In polynomial estimation, higher degree polynomials allow for better approximations of prediction windows but they also produce high variations in the output, causing the errors to accumulate over time and degrade the overall performance.
-
In the paper, Poly multi-output (PolyMO) outperforms DeepMO, which shows that rephrasing value forecasting problem as function forecasting problem improves the performance.
Code of the Week:
This week I used an LSTM model in keras to predict the minimum daily temperature in Melbourne, Austrailia. I observed the effect of different activation functions on the model’s performance. Feel free to play with other parameters such as the optimizer, epochs, batch_size etc. The source of the data is Australian Bureau of Meteorology and can be downloaded from [8]. Check out the coding exercise on my Github profile.
Thought of the Week:
The two major steps in learning the basics of any new algorithm:
-
Know the vocabulary: After you have jumped from super easy videos like RNN for dummies to super complex ones with a lot of math, there is only so much that you can retain in the long run. Therefore, in order to truly internalize whatever you have learned, simply make a concise list of all the terms and concepts related to that algorithm and imagine yourself explaining them during a hypothetical interview or a class you could be teaching in the future.
-
Code it and tweak it extensively in a programming language such as Python. Play with every parameter of that function and see how it blows up.
I think Jason@Machine Learning Mastery [1] is an excellent resource and follows the exact same approach of teaching a concise theory and a quick coding exercise in designing its ML tutorials. I love reading it!
See you next week!
References:
[1] Machine Learning Mastery
[2] Deep Multi-output Forecasting
[3] Recurrent Neural Networks
[4] Autoregressive Models
[5] ARIMA
[6] Deepmind
[7] LSTM
[8] 7 Time Series Datasets for Machine Learning